Phonetic-based feature representation with sine modulation for Mandarin speaker identification
Abstract
Speaker identification is to obtain speaker identity from audio
samples. To address this task, our research introduces a novel
phonetic-based feature representation for closed-set speaker
identification. This approach encapsulates speaker attributes
across time and frequency domains and seamlessly integrates
context information, allowing us to deduce speaker identities
effectively. We also explore the effectiveness of using distinct
word classes as distinct channels within the framework.
Moreover, we delve into the fusion of temporal and spectral
domains, leveraging a sine modulation mechanism in the
feature representation to modulate emphasis across temporal
spans, resulting in a more robust and efficient identification.
Our approach yields a peak accuracy of 85.79%, surpassing
existing MFCC-based models.
Method Overview
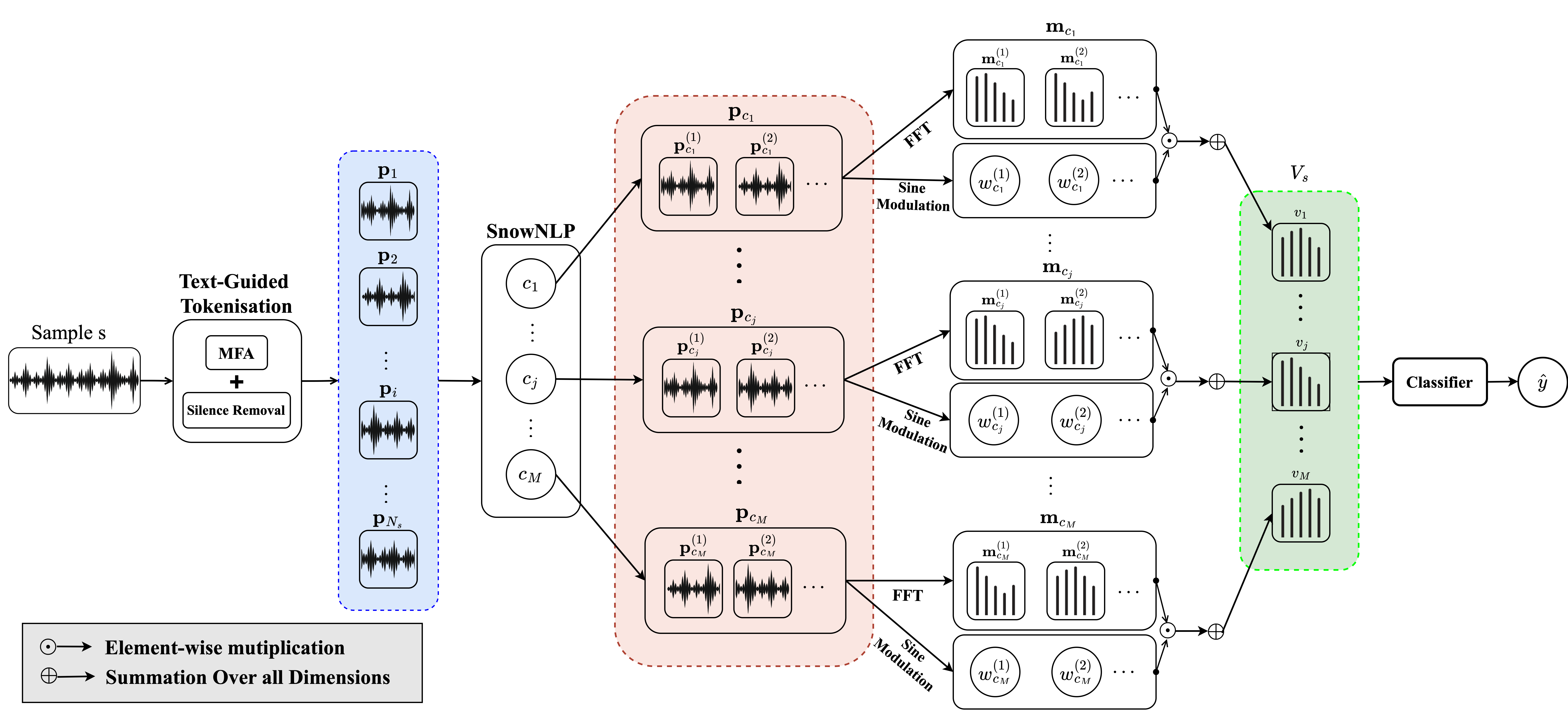
Given an input sample, our method proceeds as follows: (a) Extract phonetic tokens
based on the provided caption. (b) The tokens are then classified into M classes, resulting in a list of tokens
associated with each class. (c) Utilizing a sine function across the temporal dimension, we compute weights for each
token. By taking the weighted sum of the tokens, we generate a M dimensional feature volume, each dimension corresponding
to a class. (d) The feature volume is passed to the classifier, producing the predicted identity.
Experiment Result
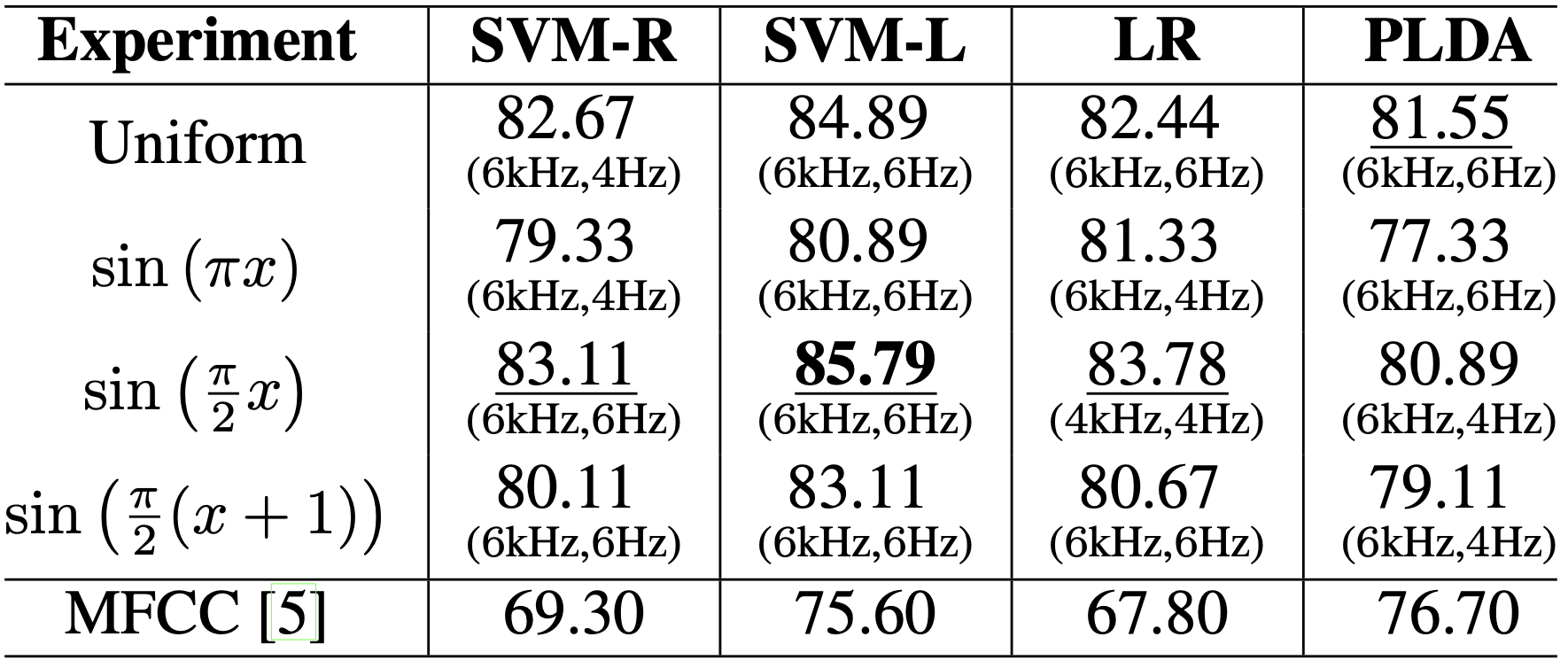
Highest prediction accuracy(%) using different sine
modulation functions with distinct configurations, compared
to MFCC. Each cell value, except MFCC, corresponds to
its optimal maximum frequency and frequency bin size configuration specified below.
Dataset
The link below contains the subset of dataset we cleaned for our project (With overlapping and transcription unmatched samples removed).
The dataset consists of 13,388 samples of 30 speakers, and 670 (~5%) of the samples are utilized as the test set.
State-of-the-art speaker identification methods in same scenario
The results of the state-of-the-art speaker identification methods evaulated:
* is based on the baseline MFCC features.
| Method | SVM-R | SVM-L | LR | PLDA |
|---|---|---|---|---|
| i-Vector* | 88.20 | 94.71 | 94.10 | 90.20 |